Computers are miraculous inventions, and have experienced equally miraculous growth over the years. We have increased clocks speeds on our CPUs to the point where physics itself gives us the middle finger. Even with such a tenacious obstacle like natural law, hardware today continues to progress with a different paradigm: the multi-core paradigm. Targeting core counts instead of clock speed, many of our machines have gone from 2 to 4 to 8 CPU cores and up in the span of a decade. Seeing this growth and change in direction, one has to wonder–have our programming languages effectively compensated for this new hardware trend?
The reality is that popular languages have not kept up all that well. Interpreted languages like Python, NodeJS, etc. have proved themselves to be high-level, increased development efficiency and productivity, and have the added boon of vibrant, open-source package ecosystems. Yet, as these languages moved from the world of simple scripts in shell/browser into the realm of customer-facing, heavy load applications, as well as being the go-to tool in heavy compute fields of data science, machine learning, the old concurrency/parallelism problem became quite apparent as many cores sat idle.
Python, or CPython in particular, still operates under the restriction of the Global Interpreter Lock, or GIL, that restricts itself to single core execution of its python bytecode. For a engineer that wants to take advantage of all the cores with a multi-threaded solution for a CPU-bound problem, this is basically a death knell. This forces the engineer to seek out means to side-step the GIL.
In this blog, I want to discuss in-depth the implications of GIL, bypass it by writing a Python library in Rust, showcasing a few things:
- The Python ecosystem sees its best libraries written in lower level languages like C, C++, and Rust. Writing a mature, optimized Python library involves knowing not only Python but a lower level language as well.
- It makes the most sense to rewrite small portions of your Python libraries in Rust: those portions being CPU-bound routines that need to take advantage of multi-core hardware. Provide low-level functionality wrapped around a high-level Python module will keep code simple and Pythonic to end users, while still unlocking modern-day hardware’s full potential.
- Rust’s unique take on memory safety with ownership system and borrow checker not only prevent memory-related bugs from occurring, but also help prevent bugs concerning multi-threaded execution as well. In addition, it has it’s own ecosystems of crates devoted to parallel/concurrent work, making it a bit more palatable compared to other languages.
CPython and the Global Interpreter Lock (GIL)
I find the best explanation for the GIL is straight from the Python Wiki itself:
In CPython, the global interpreter lock, or GIL, is a mutex that protects access to Python objects, preventing multiple threads from executing Python bytecodes at once. The GIL prevents race conditions and ensures thread safety. A nice explanation of how the Python GIL helps in these areas can be found here. In short, this mutex is necessary mainly because CPython’s memory management is not thread-safe.
https://wiki.python.org/moin/GlobalInterpreterLock
At the end of the day, the GIL still exists because Python is a language where memory management is abstracted away from the developer. This is one of the great things about Python. If the interpreter can take care of memory for you, then the developer can spend more time crafting solutions to the problem at hand rather than the mundane design problem of talking to the heap about what memory to free up and what memory to request. This is not something we want to give up for threads, especially if we want to keep Python as approachable and productive as it is.
While this approach to memory management can have a thread safe implementation, the current implementation makes it very clear that this is not the case. Attempts to remove this lock date back to 1996 with Greg Stein’s experiment, but all have failed due to complications, such slowing down single-threaded program execution.
Illustrating GIL with an Example Problem
Any CPU-bound task where work can be divided can illustrate the GIL’s implications quite well. Such problems are clinical computer science problems involving sorting, matching, finding things inside simple data structures. For this blog, I will use a simple task of counting occurrences of a substring in very large strings. That string being the entire text of a work of literary fiction.
I will be using my ThinkPad P70 machine, OS Ubuntu 22.04.2 LTS (Jammy Jellyfish), CPU is a 6th Gen Intel® Core™ i7 processor i7-6700HQ 8-core processor (appropriately multi-core given this experiment). Interpreter is Python 3.11.3. Also, for metrics, will be using pytest and pytest-benchmark to measure performance across solutions, as well as mpstat for CPU usage.
To begin, I have several text files containing some well-known works of fiction. Dune by Frank Herbert, Fellowship of the Ring by Tolkien, and Chamber of Secrets by J.K. Rowling. Within these texts, I would like to find out how many times a certain word is written per book. This is just counting substrings within a string (non-overlapping). A simple Python solution would be this: a function that accepts parallel arrays of text content, target words to count, and counts them accordingly:
def read_file(file: str) -> str:
with open(file, 'r') as fp:
text = fp.read()
return text
def word_count(text: str, target: str) -> int:
count = 0
for word in text.split():
if word == target:
count += 1
def python_sequential_word_count(
text_bodies: List[str], words: List[str]
) -> List[int]:
wcs = [
wc for wc in
map(
word_count,
text_bodies,
words
)
]
return wcs
if __name__ == '__main__':
books_on_file = ["Dune.txt", "FotR.txt", "Chamber_of_Secrets.txt"]
words_to_count = ["sand", "Bilbo", "Dobby"]
text_content = list(map(read_file, books_on_file))
word_counts = python_sequential_word_count(text_content, words_to_count)What’s that, what about just using text.count(word) for word_count? Shhhhh we will cover that possibility later 🙂
Naive, sequential, but gets the job done. word_count() here simply iterates over words, or character sequences separated by white space, and checks to see if the word matches target word. If it does, increments count. This took about 40 milliseconds on average to execute.
The workload for this problem is suited for parallel execution. A thread per book, counting characters might allow us to cut down execution time. For a novice Python developer, unaware of GIL, apart from that of Final Fantasy currency, he might implement a solution that looks like this, using native library concurrent.futures.ThreadPoolExecutor…
from typing import List
from concurrent.futures import (
ThreadPoolExecutor,
as_completed
)
def python_parallel_word_count_threads(
text_bodies: List[str], words: List[str]
) -> List[int]:
with ThreadPoolExecutor(max_workers=len(text_bodies)) as exec:
futures = [
exec.submit(word_count, text, word)
for text, word in zip(text_bodies, words)
]
wcs = []
for future in as_completed(futures):
try:
wc = future.result()
except Exception as e:
print(f"Err: {e}")
else:
wcs.append(wc)
return wcsRunning this code, the stoner might be surprised to find that the execution was about the same, or even slightly slower! Execution of this took about 44 milliseconds on average for me on my machine (click images to enlarge).
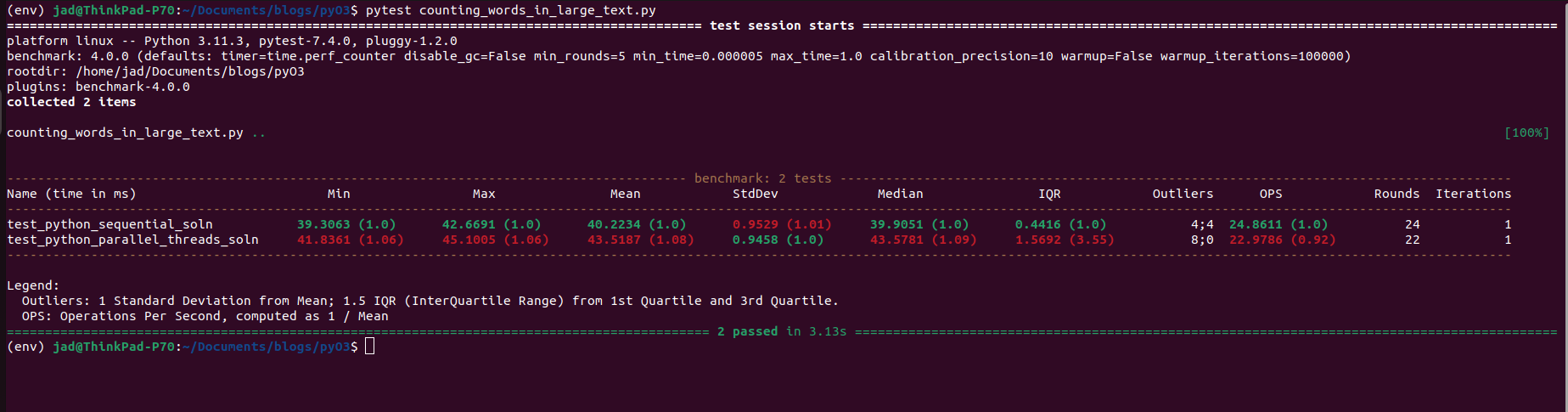
Here is where many amateur Python developers (understandably) get confused. You are given the option to create threads for work in the standard library, but running said threads in parallel? Never happens. Useful for cases of heavy I/O work for firing blocking system calls off in tandem, but computationally intensive work… not so much. For more insight, look at the CPU profiler averages for usage across my 8 cores:

For all the cores my machine has, only about one was really saturated with work (core 1). The GIL locked me behind this core, preventing the threads I created from executing in parallel. I want to see less idle time, I want to take advantage of this ThinkPad, but I am unable to with this approach.
Side-stepping the GIL within Python
Multi-processing
There are a few ways where one can successfully overcome this limitation and unlock multi-processor hardware within Python itself. One solution most Python developers will lean towards is that of multi-processing instead of multi-threading.
from typing import List
from concurrent.futures import (
ProcessPoolExecutor,
as_completed
)
def python_parallel_word_count_processes(
text_bodies: List[str], words: List[str]
) -> List[int]:
with ProcessPoolExecutor(max_workers=len(text_bodies)) as exec:
futures = [
exec.submit(word_count, text, word)
for text, word in zip(text_bodies, words)
]
wcs = []
for future in as_completed(futures):
try:
wc = future.result()
except Exception as e:
print(f"Err: {e}")
else:
wcs.append(wc)
return wcsWhile the GIL does prevent two or more threads from executing the same piece of bytecode on a process, there is nothing preventing one from spawning multiple processes of interpreters interpreting the same Python code. In this manner, we technically spawn several GILs, each with respect to one main thread executing on an interpreter process. This is where a lot of Python developers use when tackling CPU bound problem with multi-core hardware. Let’s benchmark:
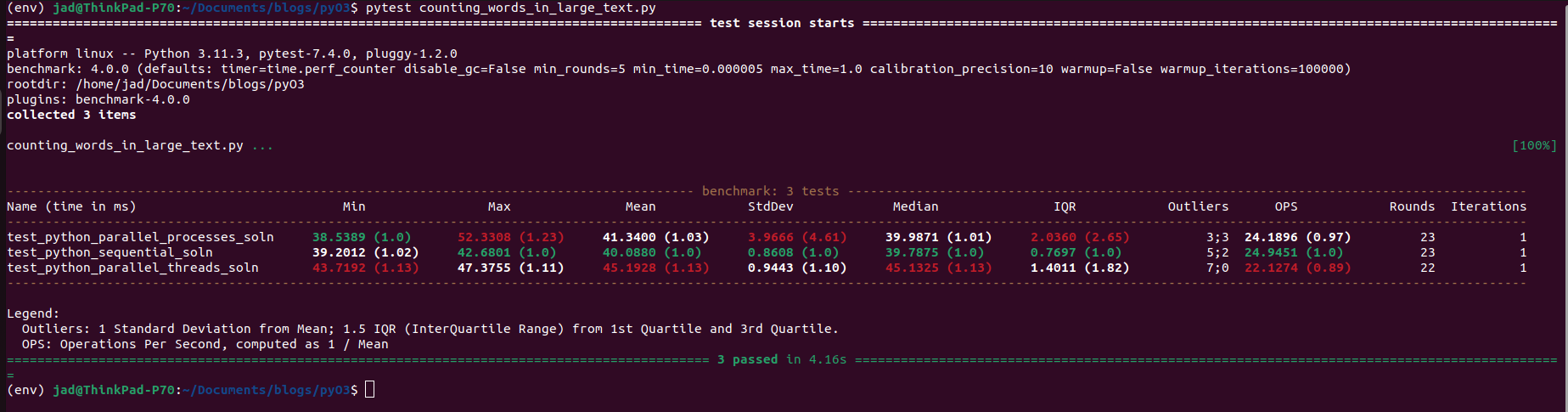
We actually see sub 40 millisecond minimum execution here for the multiprocessing approach, but results are more or less the same. Let’s try to increase the amount of text by just reading through each book 10 times. (I simply edit my read_file function to return the text concatenated 10 times return text * 10, will be using this as the metric due to how fast these following optimizations get, also easier to capture CPU utilization with a bigger task.).

The process approach is indeed faster, but only when I read through larger amounts of text. Why is this? Spawning processes is a non-trivial action. Compared to threads, where we only copy stack, register state, here we are copying the entire operating system process. Thus, for smaller problems, the act of spawning processes and copying the arguments of the function they need to execute is sometimes such a tax that it slows down to the point of the sequential solution. However, mpstat reveals that we did indeed saturate our cores with work. Cores 0, 3, 5 were indeed speed-reading these books.
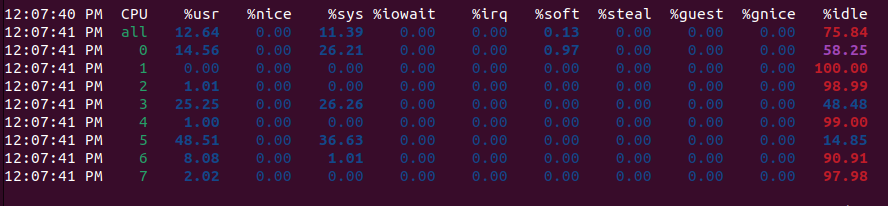
While this approach did indeed allow us to make the most of our multi-core hardware, multi-processing comes with some drawbacks:
- We share zero memory between these processes. Compare this to threads that do share memory. Due to this, we need to copy arguments (text content) across processes in order to count words. We now have 2 books in memory in some sense.
- Creating processes is a non-trivial action for an operating system. It’s taxing compared to threads.
- Context switches between processes on a core are much slower compared to those between threads.
CPython GIL-less Alternatives
CPython is not the only Python interpreter. Some of these other implementations are GIL-less, such as Jython, IronPython. One can actually write parallel code with threads in Python with these interpreters.
So is the choice just to switch interpreters and start from there? Not necessarily. These lack GIL for a reason, and that reason is that they are deeply integrated into Java VM and .NET runtimes. These all have their own means of garbage collection, memory management.
I personally have no experience with working with these interpreters, but from the outlook, inviting any of these precipitates inviting Java, .NET into your project, and learning the inner workings of these virtual machines. There are also other things to note, like how Jython currently only supports Python 2, and how Microsoft dropped IronPython support back in 2010. I lack the knowledge to make the recommendation of whether one should or should not switch to these solely on the basis of threading, but I am hesitant for sure. While I do want to test this out, I’ll elect to do that another time.
Maximizing Utilization with a Python Package Written in Rust
So where does that leave us? Well, writing the solution in a lower level language, which for Python’s case, is rather the norm when writing a library.
Chris Lattner, during his second time on the Lex Fridman podcast, reveals why this is.
C makes up a great portion of many great Python libraries. For example NumPy is a computational library that allows Python developers to do heavily computational work like convolution, image processing, matrix operations at scale. The underpinnings of this library are written in C, and bypass Python GIL by escaping the byte code as a low level routine. We need threaded work for these types of CPU-bound libraries.
While we could very easily create threaded solutions with C, writing safe multi-threaded C code is not easy. In fact, most languages are pretty ill-fitted for this work. However, Rust, according to the front page of rust-lang.com, promotes “Rust’s rich type system and ownership model guarantee memory-safety and thread-safety — enabling you to eliminate many classes of bugs at compile-time.” With Rust, we skip the heartache we would have to go through with C, and get some pretty cool third party code that we will explore.
Getting Started with PyO3
PyO3 is a set of Rust to Python bindings that allow for one to quickly write out Rust code to run in Python and vice-versa. With PyO3 one can produce Python modules and packages that are written in Rust, creating low-level optimized routines for a high-level Python API, complete with functions, classes, etc.
Getting started with PyO3 and writing your Rust library is as easy as:
- Installing up-to-date Rust, Cargo https://rustup.rs/
- Creating a Python virtual environment with python -m venv, source it.
- Installing python package maturin into development environment, a command line tool for expediting PyO3 development.
- Simply executing maturin new <your library name> to create your project directory.
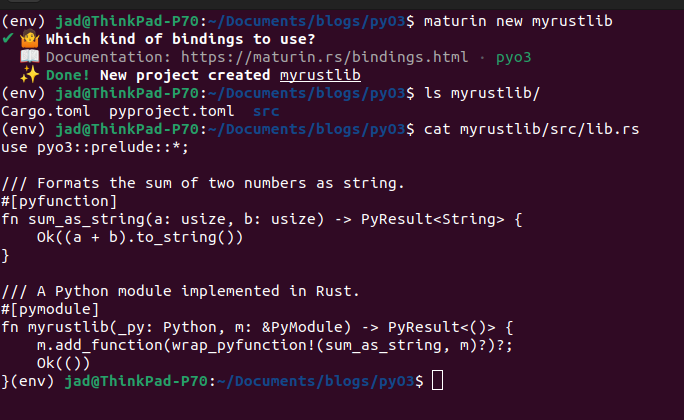
That’s it! You now have a Rust library project with some default code, Rust PyO3 dependencies listed in Cargo.toml, everything ready to go!
use pyo3::prelude::*;
/// Formats the sum of two numbers as string.
#[pyfunction]
fn sum_as_string(a: usize, b: usize) -> PyResult<String> {
Ok((a + b).to_string())
}
/// A Python module implemented in Rust.
/// Expose code here to the module
#[pymodule]
fn myrustlib(_py: Python, m: &PyModule) -> PyResult<()> {
m.add_function(wrap_pyfunction!(sum_as_string, m)?)?;
Ok(())
}From here, you can edit the template code, compile it, integrate it into the virtual environment and begin playing around with Rust code from the Python REPL.
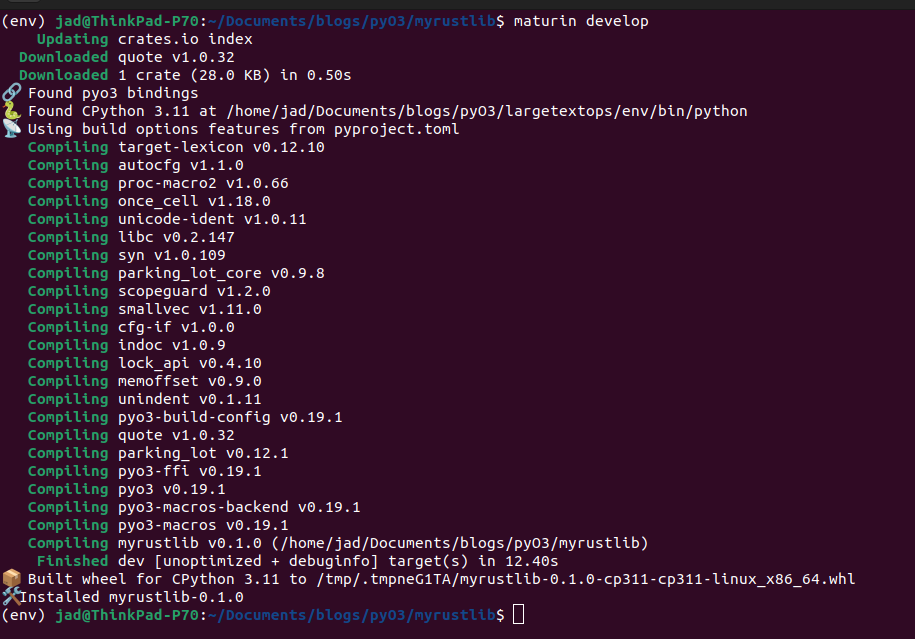
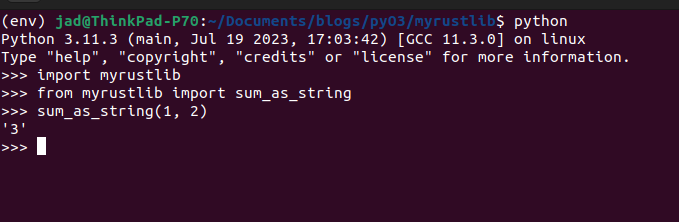
Writing Foreign Language Functions, Exploring Python Types
All right so let’s play around with this a little bit. We can write out our own function for substring counting in a string in Rust pretty simply with
// Note: in Rust, the last expression of any function is the returning
// value!
#[pyfunction]
fn word_count(text: &str, word: &str) -> usize {
text.split_whitespace().filter(|s| *s == word).count()
}Here we have to consider a few things. This function, if exposed as a function of a module, must accept two Python strings in order for this to work. Python string objects are laid out in memory differently than a Rust string slice &str. The return value also must be a dynamically sized Python integer value. If we are to make this function work, we need to accept non-Rust arguments, return non-Rust values.
PyO3 has an entire module of types that lists of a bunch of native Python types, including, integers, tuples, dictionaries, strings. The types in this module, PyList, PyTuple, PyStr, PyDict all are Rust representations of different Python objects. These are your view into what is being passed from Python to Rust, and what Rust should return to Python. This also means that in order to use Rust libraries, we will have to learn how to transform Python types to Rust types and vice versa. PyO3 actually can fill in the blanks by automatically converting Rust types on parameters and return values into corresponding PyO3 types, but for the sake of transparency, will be explicit here.
#[pyfunction]
fn word_count(_text: &PyStr, _word: &PyStr) -> PyLong {
let text: &str = _text.extract().unwrap();
let word: &str = _word.extract().unwrap();
let res = text.split_whitespace().filter(|s| *s == word).count()
PyLong::new(res)
}Again, PyO3 is smart enough to write this type of behavior for you, but working within these types is sometimes necessary when working with this crate.
Now, lets try to write out the solution that counts across text bodies and target words, parallel lists just like our Python implementations (You would want to some vetting of these Python lists, but never mind that for now).
#[pyfunction]
fn sequential_word_count(text_bodies: &PyList, words: &PyList) -> Vec<usize> {
let mut result = vec![];
for idx in 0..text_bodies.len() {
let text: &str = text_bodies[idx].extract().unwrap();
let word: &str = words[idx].extract().unwrap();
result.push(word_count(text, word));
}
result
}This is something along the lines of what we want. Assuming that these arguments are parallel lists with same size, we iterate over indexes of 0 to their length – 1 (0..text_bodies.len()). As we iterate through the list, we need to extract the python objects of the PyList as string slices so that we can use Rust standard library to iterate accordingly and pass to our word count function. We then push the result of that function to result vector that is returned. The extract method calls actually could fail hard here (a Rust panic). Python lists are heterogeneous, so we can’t expect a str value for every element. A more sturdier library might want to consider this detail more carefully.
Although this code technically works, its fails to leverage Rust iterators. Rust iterators would not only make this a bit faster, but a bit more elegant as well.
#[pyfunction]
fn sequential_word_count(text_bodies: &PyList words: &PyList) -> Vec<usize> {
text_bodies
.iter()
.map(|pyobj| pyobj.extract::<&str>().unwrap())
.zip(words.iter().map(|pyobj| pyobj.extract::<&str>().unwrap()))
.map(|(t, w)| word_count(t, w))
.collect()
}This looks intimidating, but let’s break it down. We first craft an iterator that will go through each text body of book with iter(). The Rust standard library iterator API has a function called map(), where we can pass a function that accepts the value, calls the function per item, produces and extracts it as a string slice. From there we also want the target words, so we use zip() to tie the two together, creating an iterator of two string slices, the first being the book and second being the word to count for that book. We call map() yet again, but this time simply invoke the word_count() function we have. We then use collect() which collects the values returned by word_count() into a vector of unsigned integer values. Here I leave the return value as a Rust type, entrusting PyO3 to convert this to equivalent Python list.
We then add this function to the module, compile and build (be sure to compile in release mode with maturin develop –release for speed!). Here are the results against the Python implementations.
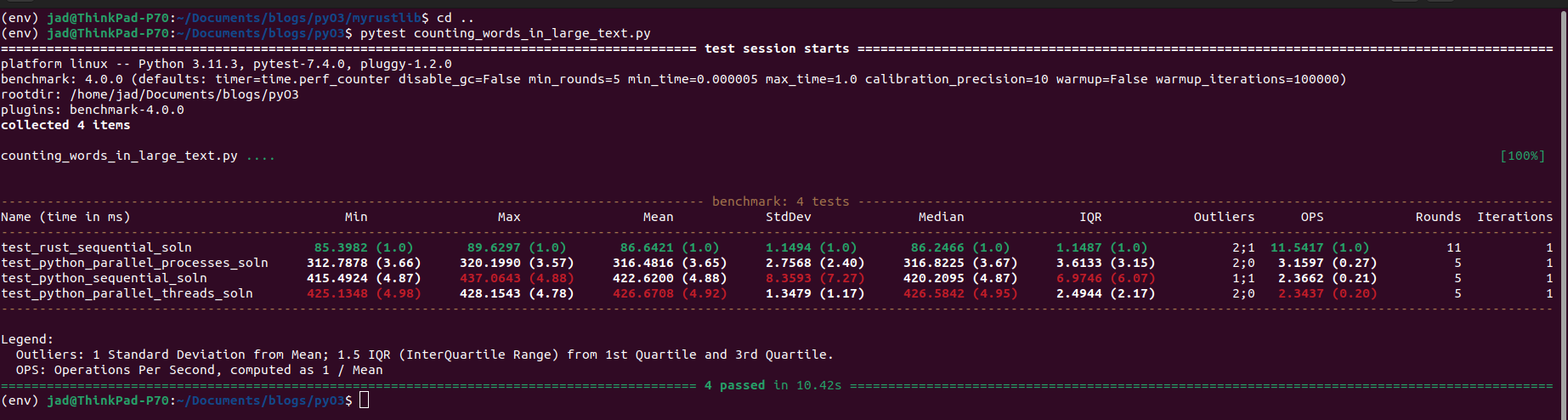
Simply the act of descending to a lower level language has given us 4-5 times the speed of Python implementations. And yet, we haven’t even implemented the parallel solution yet!
Building A Parallel Solution with Rust Crate Rayon
While one could use Rust standard library threads to start parallelizing this work (I did go ahead a make a normal std::thread solution), I wanted to shine the light on a specific third party Rust crate called rayon. The whole point of this blog post is to encourage you to use Rust to write parallel/concurrent low-level code for Python because of how effortless and bug-free the Rust experience is. And it really does not get any easier (and optimal) than with rayon.
Rayon is a powerful third party crate for safe, parallel/concurrent computing. It’s meant to take advantage of the greedy nature of computing resource scheduling, but also compensates for the possibility of dynamic load of system by electing to execute things in parallel if the workload of machine is low, or execute sequentially when CPUs are tanked with work. This is a powerful concept called work-stealing, and is accomplished with scheduling queues. If you want to read more about this idea, read the crate author’s blog.
To start working with rayon, we first need to add it to our Cargo.toml.
[package]
name = "largetextops"
version = "0.1.0"
edition = "2018"
[lib]
# ...
[dependencies]
pyo3 = { version = "0.19.1", features = ["extension-module"] }
rayon = "1.7.0"From here we can start crafting the parallel solution to this problem. You might think that includes learning the ins and outs of this crate, but rayon provides a special iterator called a ParallelIterator, created by just including rayon’s prelude and using par_iter() instead of iter().
use rayon::prelude::*;
#[pyfunction]
fn parallel_word_count(text_bodies: &PyList, words: &PyList) -> Vec<usize> {
text_bodies
.par_iter()
.map(|pyobj| pyobj.extract::<&str>().unwrap())
.zip(words.par_iter().map(|pyobj| pyobj.extract::<&str>().unwrap()))
.map(|(t, w)| word_count(t, w))
.collect()
}Using this parallel iterator, we opt in for work-stealing nature, iterating over the text bodies and target words in an optionally parallel way. It may spawn threads to produce values, but if our compute load gets high, we produce sequentially. The same iterator adapters used in the sequential solution carry over to the parallel solution, since its supports the interface and all the maps and zips we did. It’s just that easy.
The results?
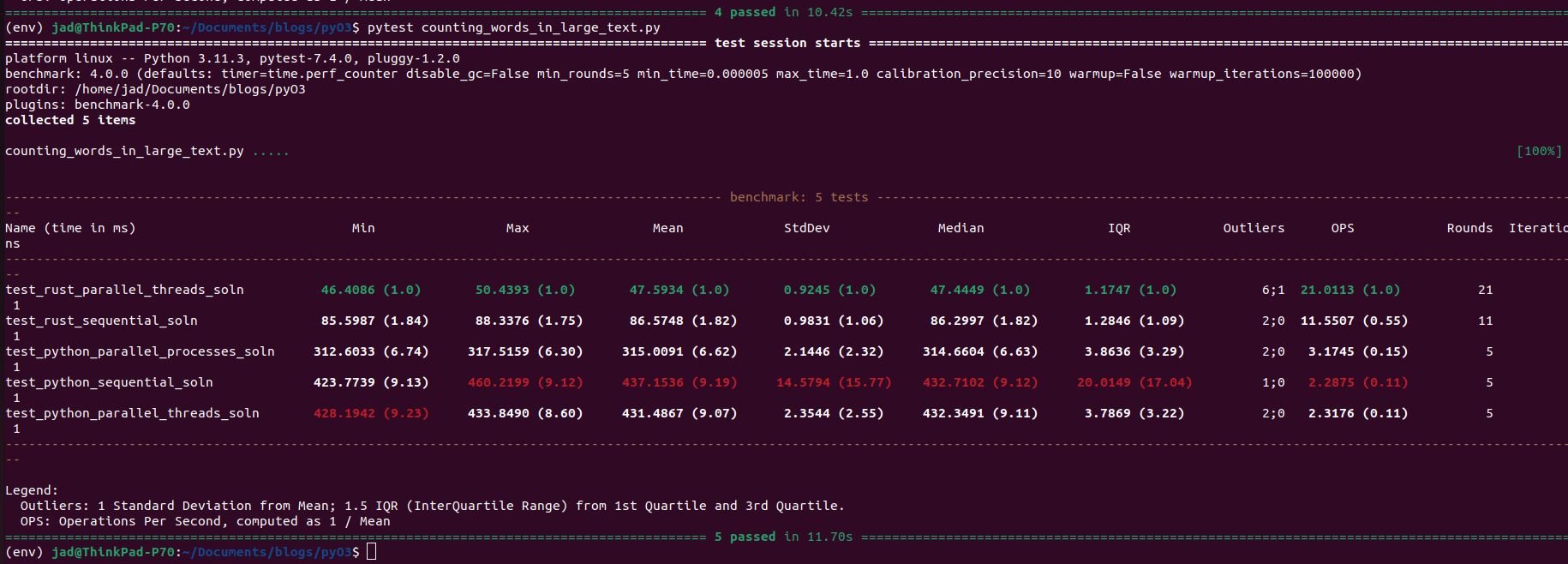
Twice the speed. As for CPU utilization?
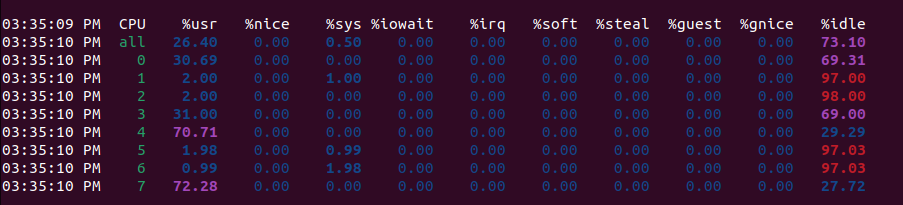
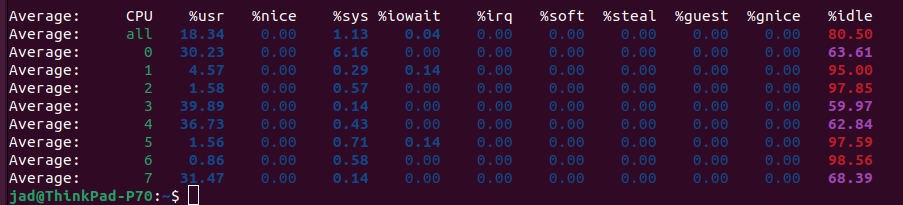
A lot more work to be shared among the cores of my laptop for sure. Saturated compared to the other attempts.
The reason why nearly every core is getting action here is simply because of how rayon operates. When we use the parallel iterator, we potentially spawn many threads, not just three. This code really taps into the power of my ThinkPad. In fact, the above mpstat captured my Code reading through each book 1000 times to get the word counts. It did this in about 4 seconds.
Hindsight 20/20 with CPython & Stringlib
Now, given that I’ve gone through all the trouble of writing lower-level Rust code for counting substrings in large bodies of text, it might seem like the native Python library is not at all well-suited for even this most basic string problem. That is not the case.
When I first started writing code for this blog post to demonstrate these ideas, my initial sequential and naive word_count function looked like this.
def word_count(text: str, target: str) -> int:
return text.count(word)
Rather straightforward, right? Compared to the other function which was more explicit and long, this solution uses the Python string method count. When I first ran my benchmarks for all the code, I was surprised to find that my naive, sequential Python solution beat every other! Even the Rust solutions!
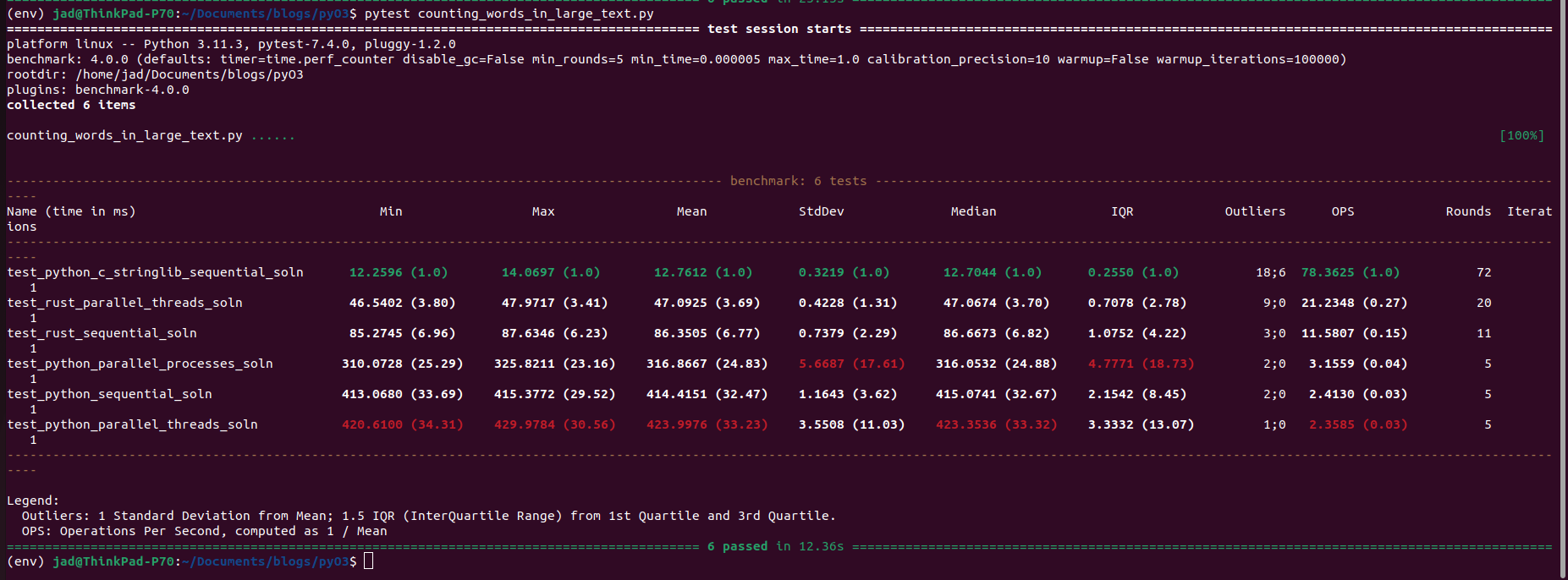
I was shocked, and a bit curious. I did some research. It turns out that count()‘s implementation is actually part a low level C library, stringlib, written way back in 2004, during an “Need for Speed” sprint for Python 2.5 in Reykjavik. This library supplied a fast string search routine that is used throughout many different string methods for Python, including index(), replace(), contains(), and count(). If you look at the source code for this library in the CPython github repository, at the top is the following description:
/* fast search/count implementation, based on a mix between boyer-moore and horspool, with a few more bells and whistles on the top... If the strings are long enough, use Crochemore and Perrin's Two-Way algorithm, which has worst-case O(n) runtime and best-case O(n/k). Also compute a table of shifts to achieve O(n/k) in more cases, and often (data dependent) deduce larger shifts than pure C&P can deduce... */
To put it simply, they cobbled together a bunch of different algorithms to provide a sub-linear (O(n/k)) string search functionality. Real nerdy stuff, but beautifully engineered. My Rust code is definitely not sub-linear, so the C code provided wins at the end of the day, making all Rust code rather moot, but an educational experience I guess.
What is to be learned here? Well, sometimes the native CPython library is very well written and optimized where it counts, and that knowledge of some of the low-level C library code may help identify the best Python solutions, often by just calling the correct method or function suited for the job, rather than manual iteration and string comparisons like I did above. Avoiding loops like this with this type of functionality is crucial for optimization. Counting substrings is something that a standard library should be able to do quickly, but when a real domain-specific problem rears its ugly head, I doubt that the Python standard library, and perhaps even external packages, will have sub-linear answers always ready.
Wrapping Up
Python is an oft-used tool in many spaces. Many of these spaces are compute intensive. Web development, data science, machine learning–an engineer has a responsibility to leverage every bit of compute the hardware has to tackle problems within these fields.
In a world of compute where concurrency/parallelism is the new paradigm, where the number of cores on our CPUs is only increasing rather than their individual clock rates, we must start considering the limitations of our Python scripts and interpreter more carefully when it comes to things like GIL. Part of this is knowing when to descend to a lower-level language to optimize CPU-bound routines where it counts.
To create truly optimal Python libraries in heavy compute fields for the modern day, write small portions of Rust code wrapped around transparent Python APIs that take the best parts of the high-level nature of Python while maximizing utilization of your hardware. Multi-threaded design is something that a lot of languages struggle with, but I think Rust tackles it better than most with its ownership system and borrower checker, as well as 3rd party crates like Rayon.
Leave a Reply