Code for this series of posts is found at https://github.com/acolite-d/llvm-tutorial-in-rust-using-inkwell.
Recently, during a binge of YouTube and coffee, I stumbled upon a talk by Johnathan Blow, titled “Preventing the Collapse of Civilization.” I’ve known about John through his Twitch streams and one of his earlier video games, Braid, and also his inclination for spouting some very hot takes on tech and games. However, this talk in particular struck a chord with my inner software industry skeptic.
Before lambasting present day shitty software and software development (in typical Johnathan Blow fashion), he first introduces a variety of historical examples of extremely advanced ancient technology that was forever lost. He touches on a variety of relics that I never knew even existed: The Lycurgus Cup, old Byzantine Empire napalm flamethrowers, the Antikythera Mechanism. These relics all had a profound amount of science and thought put into them, containing early evidence that people understood nanomaterials, chemical warfare, complex machinery. Things we would never associate with ancient civilizations. All of this understanding, forever lost, when those civilizations suffered collapse, or attrition, and the technology degraded or failed to be transferred to the next generation.
This was Johnathan’s segue into his thesis that “software is in decline.”
I found this whole talk intensely captivating. I have felt for a long time that too few developers, especially in web, understand their tools well enough to produce quality products. Think of some tech stacks nowadays: for a engineer who uses Kubernetes, what is the chance he/she knows how to operate Docker containers underneath? The chance they know how to work with Linux image running inside the container? How many engineers knowledgeable in XYZ Javascript framework understand the underlying scripting language? The V8 JIT? The browser? I’d say these chances are slim, and only getting slimmer and slimmer, with the tech being taken for granted more and more.
After watching this talk, I feel that as these teetering tech stacks get higher and higher, and we continue to become more complacent, we invite the same hubris of the ancient civilizations before us. I know this idea sounds like I am some insane tech-doomsday prophet/prepper, but I think as engineers we have a responsibility have at least some understanding, no matter how shallow, of these different layers. Especially with how much open-source tech is contained within the modern tech stack.
It starts with scholarly pursuits, reinventing the wheel.
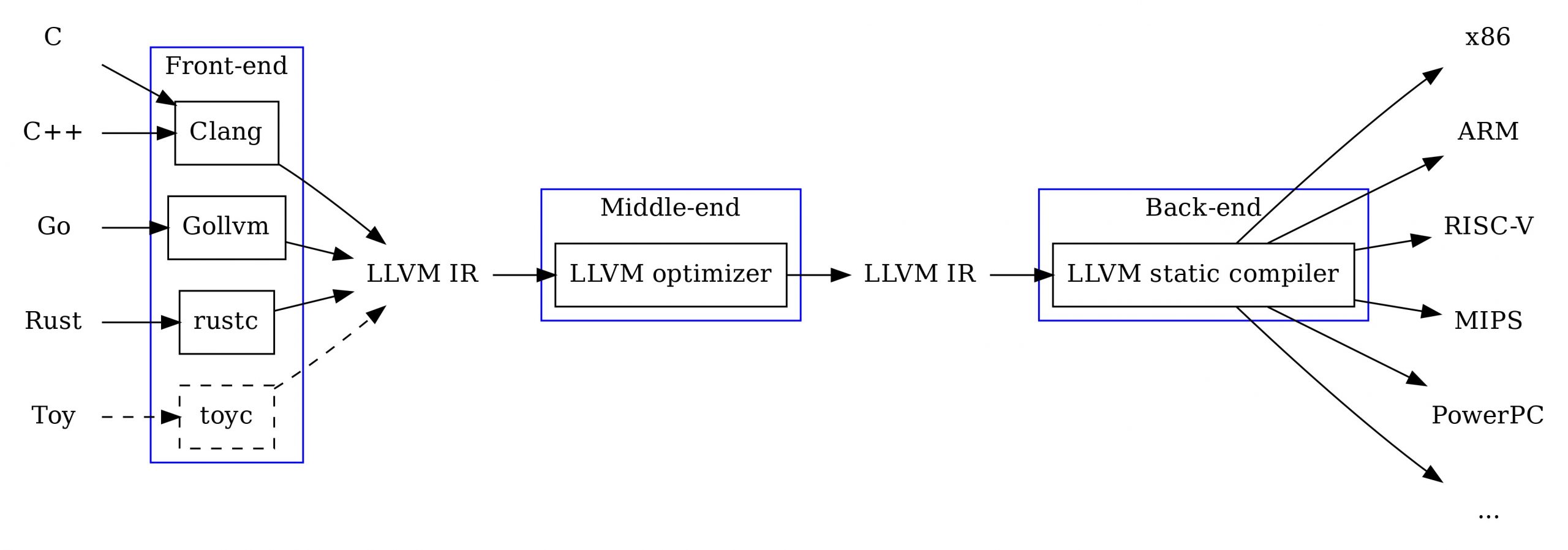
Browsers, operating systems, compilers. These things are all so big that most sane people wouldn’t dream of reinventing them, but they are impactful on such a massive scale. They all are prime candidates for this endeavor. For this series of blog posts, it will be learning about compilers via building one ourselves.
Compilers and LLVM
Readers might think that a compiler seems way too intimidating to reinvent one yourself. An implementation of any kind requires knowledge on languages, as well as knowledge about the architecture of the machine you are targeting for. Registers, instructions, CPU, the OS of the machine. Even if you make it this far and produce the right assembly sequence for a program, will it be fast? If not, you probably need to program in optimizations.
These are the same challenges that engineers who worked on implementing C/C++, Swift, Rust, Kotlin, and many others. These languages, however, all had implementations that had common infrastructure to work within: LLVM.
LLVM, from the words of the frontpage of it’s official website, is “a collection of modular and reusable compiler and toolchain technologies.” It is responsible for a renaissance of programming languages in recent years, spawning many languages that readers might use daily. It prides itself on providing developers a powerful intermediate representation (IR) to use, where other compilers use many different IRs with different stages, LLVM IR is singular, and universal across the infrastructure.
It also is not tightly bound to any one architecture, so any piece of IR is able to generate code for a variety of machines: x86_64 desktop PCs, ARM chip equipped mobile devices, IBM PowerPC, RISC-V, the list goes on and on, with every little variation of these included!
Working with LLVM means working to get source code to IR, then using that IR to optimize, analyze and compile to run on a variety of machines!
We will be using this technology to build out our own language, following the LLVM tutorial.
Kaleidoscope: LLVM’s Way of Introducing People to Language
On LLVM’s official website, there are several tutorials and guides to help the aspiring language author learn about the compiler infrastructure technology. One such tutorial is a great hands-on introduction to compiler design from top to bottom, implementing a trivial language called “Kaleidoscope.”
The language itself is a very simple Python derivative with functions, expressions, and not much else. It works exclusively with 64-bit floating point numbers to compute basic floating point math.
# Compute the x'th fibonacci number.
def fib(x)
if x < 3 then # Basic if-then-else control flow
1
else
fib(x-1)+fib(x-2)
# This expression will compute the 40th number.
fib(40)
# extern keyword, allow Kaleidoscope to call into standard
# library functions
extern sin(arg)
# Capable of being interpreted like Python in a REPL
>>> 2+2;
4
>>> def dub(num) num*2;
>>> dub(2) + 4;
8The tutorial builds out the implementation of such language from the ground up using C++ and LLVM. This lesson, however, I aim to rewrite in Rust.
Why Rewrite this Tutorial Using Rust?
The tutorial’s main goal is to introduce the technology of LLVM using this concrete example. It’s goal is to showcase LLVM API, IR generation, resources, and general logic. The introduction explains this quite clearly.
In order to focus on teaching compiler techniques and LLVM specifically, this tutorial does not show best practices in software engineering principles. For example, the code uses global variables pervasively, doesn’t use visitors, etc… but instead keeps things simple and focuses on the topics at hand.
Author(s) of “My First Language Frontend with LLVM Tutorial” on llvm.org
The tutorial expects us to be quite comfortable with C++. The code itself is simple at the beginning, but can get confusing as the tutorial progresses. As the amount of global variables and functions that use them increases, the single file containing the entire implementation of the language grows and grows and becomes more difficult to parse out global state from each function and how they interact.
I personally think it would be of great benefit to some if the code was just a bit more modular, used a bit more software convention, a bit less overarching shared state. This can be accomplished with C++ of course, but being the Rust fanboy I am, I thought it would be both interesting and educational to have an additional medium to introduce people to LLVM. With Rust’s popularity on the rise, and projects like inkwell affording people to work with LLVM using Rust, many new systems programmers might feel more comfortable with Rust. Inkwell also is a safe wrapper library around the C interface to LLVM, so it can act as a pair of training wheels, preventing misuse of API at compile time with strong Rust typing and memory safety guarantees where C++ might fail.
And, of course, my blog, my rules. Follow along with the tutorial, the blog posts, and the github repo containing the code here we will be writing here.
Writing the Frontend: Lexer
The first two chapters of the tutorial have nothing to do with LLVM really: building a parser for the Kaleidoscope language, the “frontend” so to speak.
While web devs appropriated terms like “frontend” and “backend” for distinguishing the UI from the API/databases, these are applied in the space of compilers as well. The frontend of a compiler refers to a “UI” of sorts as well, the actual source code! This involves the syntax of the source code itself, how it is given to the compiler as input, and parsed into a representation called an AST. The backend refers to taking such a tree, and translating that into various stages of intermediate representation, and finally emitting object code, assembly code, or machine code to be executed.
Use of LLVM starts somewhere in the middle here. It’s APIs cannot help us parse text into an AST, but it can be used to generate LLVM IR that can be emitted as machine code for a variety of architectures! These two chapters serve as a quick and dirty implementation of the frontend to get us to the other eight chapters where we actually use LLVM to perform backend magic.
Speaking honestly, writing a custom parser is not the most exciting of tasks to do. It mostly revolves around strings operations. This work is mundane enough that there are libraries that serve to automatically generate parser code given a high-level description of a language are prominently used in compiler frontend work. These are called “parser generators,” or more cutely referred to as “compiler compilers.” While we could easily get away with writing a 30 line grammar description of Kaleidoscope that would then feed into a parser generator to give us hundreds of lines of an optimized parser in Rust, let us use this opportunity to write something by hand as an educational experience.
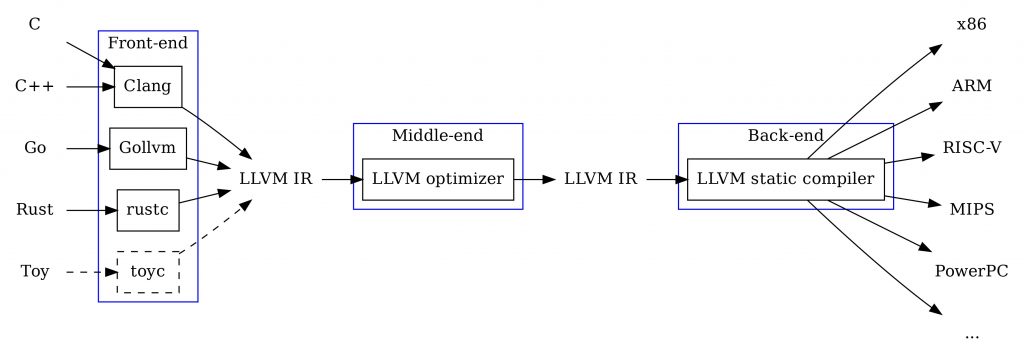
So, first things first, lexing, or tokenizing. We need to break up a given Kaleidoscope text input into the language’s primitives, like numbers, identifiers, keywords, and so on. The tutorial gives us this.
// The lexer returns tokens [0-255] if it is an unknown character, otherwise one
// of these for known things.
enum Token {
tok_eof = -1,
// commands
tok_def = -2,
tok_extern = -3,
// primary
tok_identifier = -4,
tok_number = -5,
};
static std::string IdentifierStr; // Filled in if tok_identifier
static double NumVal; // Filled in if tok_numberWe have basic units of the grammar of Kaleidoscope here. Numbers, identifiers, and keywords to identify functions like “def.” We also have some globals for storing a identifier string, and number. Let’s rewrite this as a Rust enum with variants:
#[repr(u8)]
#[derive(Debug, Clone, Copy, PartialEq)]
pub enum Token<'src> {
// Keywords
FuncDef = 1,
Extern = 2,
// Identifiers, Literal floating point numbers
Identifier(&'src str) = 3,
Number(f64) = 4,
// Operators and other goo
Operator(Ops) = 5,
OpenParen = 6,
ClosedParen = 7,
Comma = 8,
Semicolon = 9,
// This is included for all strings I cannot understand
Unknown(&'src str) = 10,
}
// Operators are their own enum as well, could easily be expanded to more
#[repr(u8)]
#[derive(Debug, Clone, Copy, PartialEq)]
pub enum Ops {
Plus = 0,
Minus = 1,
Mult = 2,
Div = 3,
}We will see that the enum includes both the integer tag for a token, and data as well! Rust algebraic data type enums allow us to form so called tagged unions all in one enum without reaching for a union keyword. The benefit to this is we effectively remove two global variables used at the start!
Also note the additional tokens–operators, commas, semicolons. Throughout the tutorial, things like parenthesis, commas, and semicolons are treated as tokens without being given a associated enum (they are actually stored in a global string variable called CurTok). I found this to be a bit misleading, confusing, so I decided to append the enum with these things that seem to me to be effective tokens as well!
At the same time, we also use string references rather than owned copies of strings. If we look at Token::Identifier, we will find it contains a reference or slice of string with the ‘src lifetime. I find that it is a bit wasteful to use std::string copies in the tutorial, when one could take references to the strings from the source code itself. This means we copy nothing from the given text input, and we simply take references from it. Because we are working with references that need explicit lifetimes, I have given the references to these strings the src lifetime, as in source, or source code.
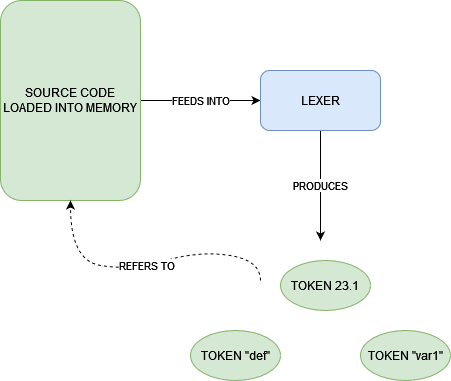
Lifetimes can be a foreign thing to some, so for those that are confused, think of it this way: since I am copying nothing from the text input when I am lexing, I take pointers that are slices of variable names and function names from the source. These pointers point to the original text that, say, was loaded into memory when I gave it as an argument to the compiler. The file is opened, put on the heap, and is eventually freed up. Let’s equate source lifetime to everything colored green here. Rust won’t compile something it understands may or may not create dangling references to the source. The ‘src lifetime is our way of telling Rust that these string references inside our enum live for at least as long as the source code we give our program, coloring in a reference with a particular color to clarify.
So then the problem is, how to translate strings to these tokens? One could create a function where ignore the whitespace, and just piece by piece tokens string references:
fn tokenize(string: &str) -> Token {
use Token::*;
match string {
// Keywords
"def" => FuncDef,
"extern" => Extern,
// Operators
"+" => Operator(Ops::Plus),
"-" => Operator(Ops::Minus),
"*" => Operator(Ops::Mult),
"/" => Operator(Ops::Div),
// Parenthesis
"(" => OpenParen,
")" => ClosedParen,
//Delimiters
"," => Comma,
";" => Semicolon,
// Everything else
text => {
if let Ok(num) = text.parse::<f64>() {
Number(num)
} else {
if text.chars().nth(0).unwrap().is_alphabetic() {
Identifier(text)
} else {
Unknown(text)
}
}
}
}
}
fn main() {
let src_code = " 12.3 def var1 ";
for word in src_code.split_whitespace() {
dbg!(tokenize(word))
}
// prints:
// Token::Number(12.3)
// Token::FuncDef
// Token::Identifier(&"var1")
// ...
}So here’s the general idea behind creating a token, but what do we pass to the parser to evaluate everything to a tree? The original tutorial uses a global buffer of sorts with different data found in different variables depending on the current token being read.
static std::string IdentifierStr; // Filled in if tok_identifier
static double NumVal; // Filled in if tok_number
/// gettok - Return the next token from standard input.
static int gettok() {
static int LastChar = ' ';
// Skip any whitespace.
while (isspace(LastChar))
LastChar = getchar();
if (isalpha(LastChar)) { // identifier: [a-zA-Z][a-zA-Z0-9]*
//...
}
/// CurTok/getNextToken - Provide a simple token buffer.
/// CurTok is the current
/// token the parser is looking at.
/// getNextToken reads another token from the
/// lexer and updates CurTok with its results.
static int CurTok;
static int getNextToken() { return CurTok = gettok(); }If look at this long enough, we will eventually figure out that they implemented an iterator-like interface to this global buffer. getNextToken() is just a way to progress the iterator like we would with next() in Python, C++ STL, Rust, or really any language with a similar iterator API. Similarly, the EOF token is the stop iteration symbol that is the signal to the parser that there is nothing left to parse. We could easily make an actual iterator out of this.
But wouldn’t it be cool if we could string together the iterator for iterating over strings, ignoring whitespace with split_whitespace, but convert the items it produces from &’src str to our Tokens<‘src>? That’s basically an iterator adapter!
// Iterator adapter for tokens, technically the generic "I" could just be
// SplitWhitespace, but we can go ahead and make it generic over any
// iterator that produces strings!
#[derive(Debug)]
pub struct Tokens<'src, I> {
iter: I,
leftover_slice: Option<&'src str>,
}
impl<'src, I> Iterator for Tokens<'src, I>
where
I: Iterator<Item = &'src str>,
{
type Item = Token<'src>;
fn next(&mut self) -> Option<Self::Item> {
let mut slice = self.leftover_slice
.take()
.or_else(|| self.iter.next())?;
// This bit will help use break apart string slices that may
// contain multiple tokens, like "2+2", "x-1", and prevent
// lexer from producing Token::Unknown("2+2")
if slice.len() > 1 {
if let Some(pos) = slice.find(Token::is_single_char_token) {
if pos != 0 {
let (immed, rest) = slice.split_at(pos);
slice = immed;
self.leftover_slice.replace(rest);
} else {
let (immed, rest) = slice.split_at(1);
slice = immed;
self.leftover_slice.replace(rest);
}
}
}
Some(tokenize(slice))
}
}Iterator adapters will require a trait to impose on a primitive type like a str. So we will call ours Lex.
// A trait with an interface for creating that iterator
pub trait Lex {
fn lex(&self) -> Tokens<SplitWhitespace>;
}
// Implement it for any string
impl Lex for str {
fn lex(&self) -> Tokens<SplitWhitespace> {
Tokens::new(self.split_whitespace())
}
}
impl<'src, I> Tokens<'src, I> {
pub fn new(iter: I) -> Self {
Self {
iter,
leftover_slice: None,
}
}
}
// You can use the trait by importing from the module, calling it with
// any given string!
use crate::frontend::lexer::Lex;
let input = " def double(x) x*2";
let tokens = input.lex();
tokens.next() // Some(FuncDef)
tokens.next() // Some(Identifier("double"))
tokens.next() // Some(OpenParen)...To wrap up, I also included tests to check my work for sanity. Supplying various strings to parse with my Lex trait to see if I got expected results. The cargo testing framework is awesome here, and can be run with a simple “cargo test.”
#[cfg(test)]
mod tests {
use super::*;
use Ops::*;
use Token::*;
#[test]
fn lexing_nums() {
let input = " 2.3 4.654345 700 0.23423 ";
let tokens = input.lex();
assert_eq!(
tokens.collect::<Vec<Token>>(),
vec![
Number(2.3),
Number(4.654345),
Number(700.0),
Number(0.23423),
]
);
}
#[test]
fn lexing_identifiers() {
let input = " var1 xyz GLBAL some_count ";
let tokens = input.lex();
assert_eq!(
tokens.collect::<Vec<Token>>(),
vec![
Identifier(&"var1"),
Identifier(&"xyz"),
Identifier(&"GLBAL"),
Identifier(&"some_count"),
]
);
}
#[test]
fn lexing_operators() {
let input = " + - * / ";
let tokens = input.lex();
assert_eq!(
tokens.collect::<Vec<Token>>(),
vec![
Operator(Plus),
Operator(Minus),
Operator(Mult),
Operator(Div),
]
);
}
#[test]
fn lexing_calls() {
let mut input = " func1(2, 5, 10) ";
let mut tokens = input.lex();
assert_eq!(
tokens.collect::<Vec<Token>>(),
vec![
Identifier(&"func1"),
OpenParen,
Number(2.0),
Comma,
Number(5.0),
Comma,
Number(10.0),
ClosedParen,
]
);
input = " func2 () ";
tokens = input.lex();
assert_eq!(
tokens.collect::<Vec<Token>>(),
vec![Identifier(&"func2"), OpenParen, ClosedParen,]
);
input = " func3 (x + 2) ";
tokens = input.lex();
assert_eq!(
tokens.collect::<Vec<Token>>(),
vec![
Identifier(&"func3"),
OpenParen,
Identifier(&"x"),
Operator(Ops::Plus),
Number(2.0),
ClosedParen,
]
);
}
#[test]
fn lexing_function_defs() {
let mut input = " def myCalculation(arg1 arg2) ";
let mut tokens = input.lex();
assert_eq!(
tokens.collect::<Vec<Token>>(),
vec![
FuncDef,
Identifier(&"myCalculation"),
OpenParen,
Identifier(&"arg1"),
Identifier(&"arg2"),
ClosedParen,
]
);
input = " def noParamsCall ( ) ";
tokens = input.lex();
assert_eq!(
tokens.collect::<Vec<Token>>(),
vec![
FuncDef,
Identifier(&"noParamsCall"),
OpenParen,
ClosedParen,
]
);
}
}kaleidrs$ cargo test
Compiling kaleidrs v0.1.0 (/home/jdorman/projects/langs-test/kaleidrs)
Finished `test` profile [unoptimized + debuginfo] target(s) in 1.57s
Running unittests src/main.rs (target/debug/deps/kaleidrs-25c59258b433346f)
running 6 tests
test frontend::lexer::tests::lexing_function_defs ... ok
test frontend::lexer::tests::lexing_operators ... ok
test frontend::lexer::tests::lexing_identifiers ... ok
test frontend::lexer::tests::lexing_calls ... ok
test frontend::lexer::tests::lexing_mixed ... ok
test frontend::lexer::tests::lexing_nums ... ok
test result: ok. 6 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00sWriting the Frontend: Parser & Abstract Syntax Tree
We have a means of translating text input into tokens, now we have to take basic units of the language, the numbers, identifying names, operators, and bunch them together into a higher construct called an abstract syntax tree.
AST
The tree in the tutorial is rather straightforward:
/// ExprAST - Base class for all expression nodes.
class ExprAST {
public:
virtual ~ExprAST() = default;
};
/// NumberExprAST - Expression class for numeric literals like "1.0".
class NumberExprAST : public ExprAST {
double Val;
public:
NumberExprAST(double Val) : Val(Val) {}
};
/// VariableExprAST - Expression class for referencing a variable, like "a".
class VariableExprAST : public ExprAST {
std::string Name;
public:
VariableExprAST(const std::string &Name) : Name(Name) {}
};
/// BinaryExprAST - Expression class for a binary operator.
class BinaryExprAST : public ExprAST {
char Op;
std::unique_ptr<ExprAST> LHS, RHS;
public:
BinaryExprAST(char Op, std::unique_ptr<ExprAST> LHS,
std::unique_ptr<ExprAST> RHS)
: Op(Op), LHS(std::move(LHS)), RHS(std::move(RHS)) {}
};
/// CallExprAST - Expression class for function calls.
class CallExprAST : public ExprAST {
std::string Callee;
std::vector<std::unique_ptr<ExprAST>> Args;
public:
CallExprAST(const std::string &Callee,
std::vector<std::unique_ptr<ExprAST>> Args)
: Callee(Callee), Args(std::move(Args)) {}
};
/// PrototypeAST - This class represents the "prototype" for a function,
/// which captures its name, and its argument names (thus implicitly the number
/// of arguments the function takes).
class PrototypeAST {
std::string Name;
std::vector<std::string> Args;
public:
PrototypeAST(const std::string &Name, std::vector<std::string> Args)
: Name(Name), Args(std::move(Args)) {}
const std::string &getName() const { return Name; }
};
/// FunctionAST - This class represents a function definition itself.
class FunctionAST {
std::unique_ptr<PrototypeAST> Proto;
std::unique_ptr<ExprAST> Body;
public:
FunctionAST(std::unique_ptr<PrototypeAST> Proto,
std::unique_ptr<ExprAST> Body)
: Proto(std::move(Proto)), Body(std::move(Body)) {}
};Seems like a lot, but given one knows some C++ and OOP, one will find it quite easy to grok out the logic here. The tree consists of ExprAST nodes which serve as a base abstract class for all nodes to inherit from. The builds itself up with various child classes found here. They are given some constructors, and a few getter methods. Note that non-leaf nodes have a std::unique_ptr<ExprAST> member, which makes it a subtree with children that could effectively be any type inheriting from the base class. Leaves lack this. We have number and variable leaf nodes, as well as possibly recursive node structures like calls and binary expressions that could go on and on… (thing 1 + 2 + 3 + …, func1(func2(…))).
Also note the use of dynamic dispatch here–std::unique_ptr<ExprAST> could point to any type of node that is a child of the abstract class.
Rust does not have classes or inheritance, but it does have traits. We could create an ASTExpr trait to form the interface of our expression nodes, then implement that for whatever tree member we need!
pub trait ASTExpr: Debug {}
// Number Expressions
#[derive(Debug, DynPartialEq, PartialEq)]
pub struct NumberExpr(pub f64);
// This part is important for associating the struct with trait!
impl ASTExpr for NumberExpr {}
// Variable Expressions
#[derive(Debug, DynPartialEq, PartialEq)]
pub struct VariableExpr {
pub name: String,
}
impl ASTExpr for VariableExpr {}
// Binary Expressions
#[derive(Debug, DynPartialEq, PartialEq)]
pub struct BinaryExpr {
pub op: Ops,
pub left: Box<dyn ASTExpr>,
pub right: Box<dyn ASTExpr>,
}
impl ASTExpr for BinaryExpr {}
// Function Call Expressions
#[derive(Debug, DynPartialEq, PartialEq)]
pub struct CallExpr {
pub name: String,
pub args: Vec<Box<dyn ASTExpr>>,
}
impl ASTExpr for CallExpr {}
// Prototype
#[derive(Debug, DynPartialEq, PartialEq)]
pub struct Prototype {
pub name: String,
pub args: Vec<String>,
}
// Function
#[derive(Debug, DynPartialEq, PartialEq)]
pub struct Function {
pub proto: Box<Prototype>,
pub body: Box<dyn ASTExpr>,
}In Rust, we have to be explicit when we use any form of dynamic dispatch. With C++, we used std::unique_ptr<ExprAST> to identify this nature, but here we use basically the same type of heap pointer, a box, which is effectively a unique pointer as well, and use the “dyn” keyword along with our AST trait to identify it as dynamically dispatched. This is called a trait object. The only difference here is a trait object is a fat pointer containing two pointers: one to the data, and another pointing directly to the implementation of ASTExpr for that data. While in C++ we just have a single pointer to data.
I’ve also made members of this tree public. I find that getters here are a bit unnecessary. Makes things a bit more simpler and workable outside the frontend module.
Readers might be asking, “John, what happened to the ‘src lifetime, string references, and avoiding copying strings? And what’s with the DynPartialEq derive? That does not look like standard library trait.” The reality is that the original implementation did store references instead of copies of strings in the tree, and associated the lifetime of each type of expression with source.
What forced my hand? Testing. If my AST implements PartialEq, I could compare a parse result against an expected tree to see if they are the same with assert_eq! macros in my tests. The problem is, how to check the equality of two trait objects that could be of various types Box<dyn AST>‘s?
An Aside: Alternative AST with Enum Dispatch
The more I thought about how difficult everything became when using dynamic dispatched trait objects, the more I started thinking to myself, “God, there has to be a better way to not copy strings while also deriving PartialEq!” After some thought, I discovered one could avoid dynamic dispatch entirely by just using an enum.
// ast_v2.rs
use crate::frontend::lexer::Ops;
// Enum dispatch instead?
// - less indirection trait objects and Vtables, faster
// - keep string references, no copies
// - No trait objects so I can easily derive PartialEq
#[derive(Debug, Clone, PartialEq)]
pub enum ASTExpr<'src> {
NumberExpr(pub f64),
VariableExpr(pub &'src str),
BinaryExpr {
pub op: Ops
pub left: Box<ASTExpr<'src>>,
pub right: Box<ASTExpr<'src>>,
},
CallExpr {
pub name: &'src str,
pub args: Vec<Box<ASTExpr<'src>>>,
},
}
// Prototype
#[derive(Debug, PartialEq)]
pub struct Prototype<'src> {
pub name: &'src str,
pub args: Vec<&'src str>,
}
// Function
#[derive(Debug, PartialEq)]
pub struct Function<'src> {
pub proto: Box<Prototype>,
pub body: Box<ASTExpr<'src>>,
}Note that I settle on using this AST instead in the next chapter, where I do a refactor and explain a bit more in detail!
Recursive Descent Parser
With the tree defined, the next problem deals with how to use the tokens to craft the tree. This is done via recursion, hence “recursive descent parser.” What the hell is that?
Imagine a patchwork of functions, each dedicated to creating a different part of our AST. Nodes higher up the tree might call functions to create nodes on the lower level to produce children.
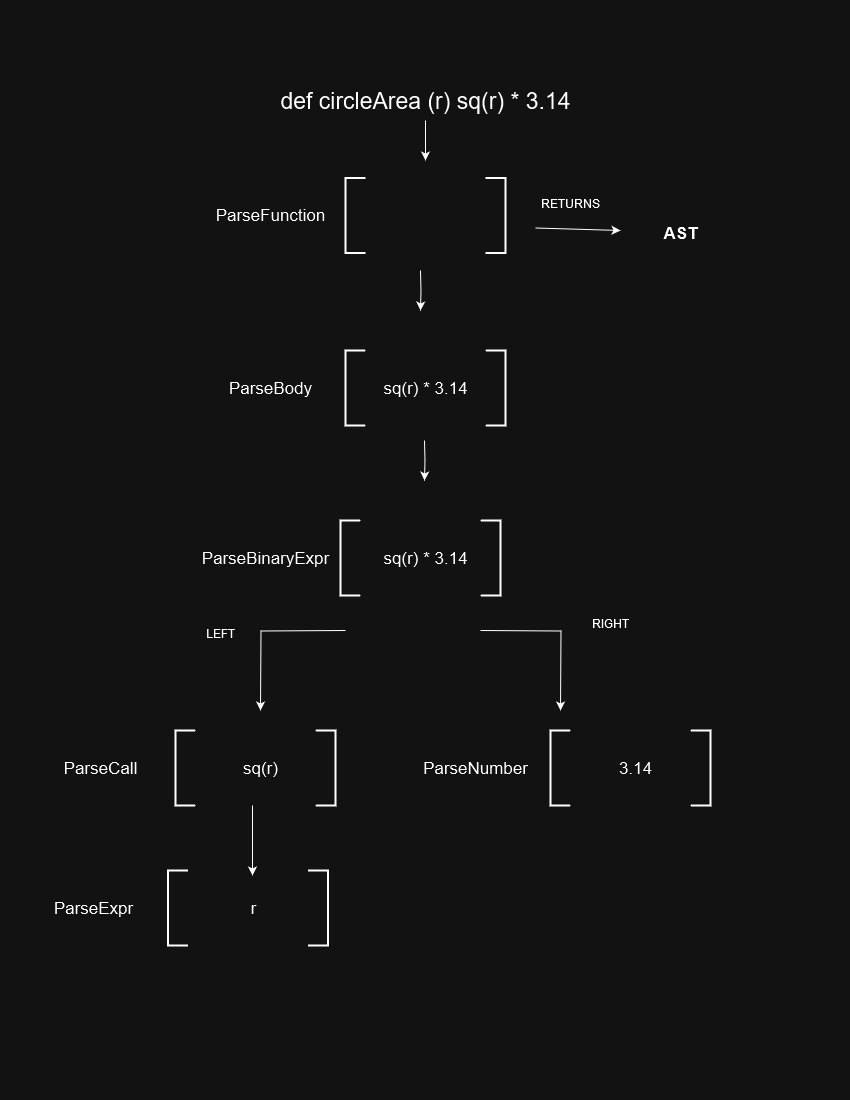
Each of these functions is responsible for handling the creation of a different part of the tree. In the tutorial, many of these bubble up different nodes to their callers, in form of std::unique_ptr<ASTExpr>. The result that bubbles up is the tree representative of the input.
/// primary
/// ::= identifierexpr
/// ::= numberexpr
/// ::= parenexpr
static std::unique_ptr<ExprAST> ParsePrimary() {
switch (CurTok) {
default:
return LogError("unknown token when expecting an expression");
case tok_identifier:
return ParseIdentifierExpr();
case tok_number:
return ParseNumberExpr();
case '(':
return ParseParenExpr();
}
}
/// numberexpr ::= number
static std::unique_ptr<ExprAST> ParseNumberExpr() {
auto Result = std::make_unique<NumberExprAST>(NumVal);
getNextToken(); // consume the number
return std::move(Result);
}
/// parenexpr ::= '(' expression ')'
static std::unique_ptr<ExprAST> ParseParenExpr() {
getNextToken(); // eat (.
auto V = ParseExpression();
if (!V)
return nullptr;
if (CurTok != ')')
return LogError("expected ')'");
getNextToken(); // eat ).
return V;
}
/// identifierexpr
/// ::= identifier
/// ::= identifier '(' expression* ')'
static std::unique_ptr<ExprAST> ParseIdentifierExpr() {
std::string IdName = IdentifierStr;
getNextToken(); // eat identifier.
if (CurTok != '(') // Simple variable ref.
return std::make_unique<VariableExprAST>(IdName);
// Call.
getNextToken(); // eat (
std::vector<std::unique_ptr<ExprAST>> Args;
if (CurTok != ')') {
while (true) {
if (auto Arg = ParseExpression())
Args.push_back(std::move(Arg));
else
return nullptr;
if (CurTok == ')')
break;
if (CurTok != ',')
return LogError("Expected ')' or ',' in argument list");
getNextToken();
}
}
// Eat the ')'.
getNextToken();
return std::make_unique<CallExprAST>(IdName, std::move(Args));
}None of these functions take any arguments, they all cite the global buffer and advance tokens with the getNextToken function. Because we crafted the iterator in the lexing part of this blog post, we will rewrite these functions to accept the token iterator.
/// primary
/// ::= identifierexpr
/// ::= numberexpr
/// ::= parenexpr
fn parse_primary<'src>(
tokens: &mut Peekable<impl Iterator<Item = Token<'src>>>,
) -> ParseResult<'src> {
match tokens.peek() {
Some(Token::Identifier(_)) => parse_identifier_expr(tokens),
Some(Token::Number(_)) => parse_number_expr(tokens),
Some(Token::OpenParen) => parse_paren_expr(tokens),
Some(unexpected) => Err(ParserError::UnexpectedToken(*unexpected)),
None => Err(ParserError::UnexpectedEOI),
}
}
/// numberexpr ::= number
fn parse_number_expr<'src>(
tokens: &mut Peekable<impl Iterator<Item = Token<'src>>>
) -> ParseResult<'src> {
if let Some(Token::Number(num)) = tokens.next() {
Ok(Box::new(NumberExpr(num)))
} else {
panic!("Only call this function when you expect a number!")
}
}
/// parenexpr ::= '(' expression ')'
fn parse_paren_expr<'src>(
tokens: &mut Peekable<impl Iterator<Item = Token<'src>>>,
) -> ParseResult<'src> {
let _paren = tokens.next();
let expr = parse_expression(tokens);
match tokens.next() {
Some(Token::ClosedParen) => expr,
Some(unexpected) => Err(ParserError::UnexpectedToken(unexpected)),
None => Err(ParserError::UnexpectedEOI),
}
}
fn parse_expression<'src>(
tokens: &mut Peekable<impl Iterator<Item = Token<'src>>>,
) -> ParseResult<'src> {
let lhs = parse_primary(tokens)?;
parse_binop_rhs(tokens, lhs, 0)
}
/// identifierexpr
/// ::= identifier
/// ::= identifier '(' expression* ')'
fn parse_identifier_expr<'src>(
tokens: &mut Peekable<impl Iterator<Item = Token<'src>>>,
) -> ParseResult<'src> {
//more of the sameI’ve also made the parameter a Peekable iterator to allow for use of the peek() method for iterators, which will produce a reference to the next token without consuming it right away, which is a property of the original implementation of the global token buffer, where we can look at the current token enum value. In addition, I use the Result enum to handle the cases where I encounter syntax issues like expecting tokens when they are not there, or encountering unexpected tokens, reaching the end of input early, so on and so forth.
I use the thiserror crate for this. It is a third party Rust crate for creating really expressive errors without implementing the std::error::Error trait. I wrap the errors in a alias of ParseResult<‘src>.
use thiserror::Error;
#[derive(Error, PartialEq, Debug)]
pub enum ParserError<'src> {
#[error("Unexpected token: {0:?}")]
UnexpectedToken(Token<'src>),
#[error("Reached end of input expecting more")]
UnexpectedEOI,
#[error("Expected token: {0:?}")]
ExpectedToken(Token<'src>),
}
type ParseResult<'src> = Result<Box<dyn AST>, ParserError<'src>>;Apart from that, the rest of the code is a mirror image of the tutorial C++ code, same function names, just Rust. The final recursive parser can be found at https://github.com/acolite-d/llvm-tutorial-in-rust/blob/main/src/frontend/lexer.rs. Follow along with the original tutorial’s second chapter for a play by play guide on how each function in the recursive descent parser work, since I really only translated everything to Rust.
The tutorial ends with a demonstration of the work we’ve done so far with a small read-evaluate-print loop (REPL) that takes in Kaleidoscope code and produces ASTs, logging errors when necessary. I’ve created a similar REPL in repl.rs can demonstrates much of the same, printing out the debug representation of the tree with the dbg!() macro.
kaleidrs$ cargo run
Compiling kaleidrs v0.1.0 (/home/jdorman/projects/langs-test/kaleidrs)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 1.72s
Running `target/debug/kaleidrs`
Ready >> 2 + 2;
Parsed a top-level expression.
[src/repl.rs:61:21] ast = Function {
proto: Prototype {
name: "__anonymous_expr",
args: [],
},
body: BinaryExpr {
op: Plus,
left: NumberExpr(
2.0,
),
right: NumberExpr(
2.0,
),
},
}
Ready >> sum / divisor;
Parsed a top-level expression.
[src/repl.rs:61:21] ast = Function {
proto: Prototype {
name: "__anonymous_expr",
args: [],
},
body: BinaryExpr {
op: Div,
left: VariableExpr {
name: "sum",
},
right: VariableExpr {
name: "divisor",
},
},
}
Ready >> def circleArea (r) sq(2) * 3.14;
Parsed a function definition.
[src/repl.rs:35:21] ast = Function {
proto: Prototype {
name: "circleArea",
args: [
"r",
],
},
body: BinaryExpr {
op: Mult,
left: CallExpr {
name: "sq",
args: [
NumberExpr(
2.0,
),
],
},
right: NumberExpr(
3.14,
),
},
}
Ready >> 4ewsdf
Error on top-level: Unexpected token: Unknown("4ewsdf")
Ready >> myFunc(arg1 ;
Error on top-level: Unexpected token: Semicolon
Ready >> Frontend Finished: Where to from Here?
If there is anything to be gained here, it is an appreciation for the work parser generators do abstracting this whole process over nearly any possible language. We could have saved ourselves some trouble by leveraging one of the many that are available on crates.io, like pest, peg, or even the parsing combinatorics library nom, but now we can say we have handcrafted this parser for a compiler!
No we move on to the third chapter, where we finally get to use LLVM…

Leave a Reply